Events
Subscribe to Filter
Importing into Google Calendar
In the left-hand column of the Google Calendar main view, click the arrow to the right of "Other calendars" and click "Add by URL". In the form that appears, paste in the URL from the box above, and click the button to confirm.
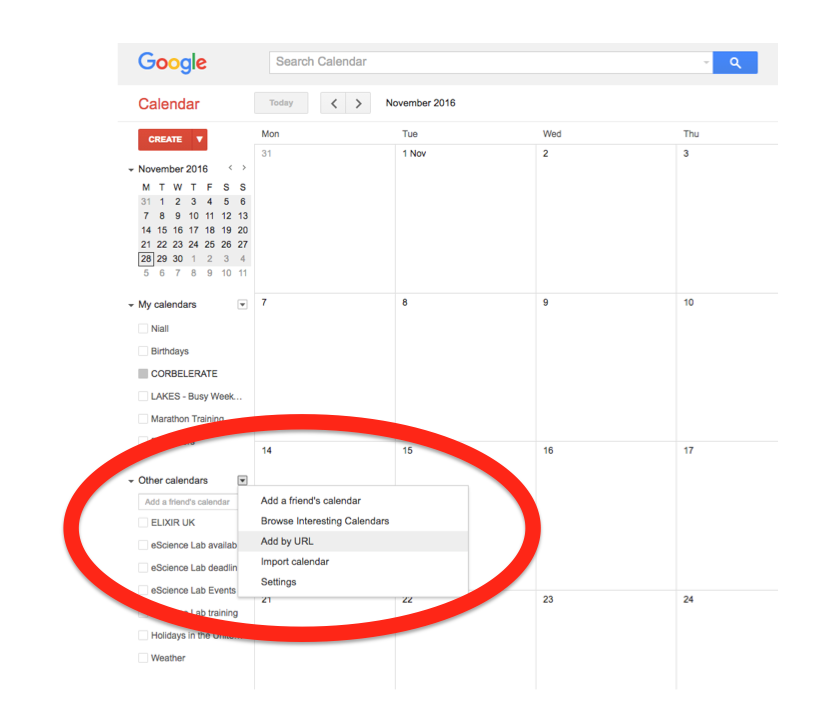
Please note, it may take a while for newly created events in TeSS to synchronise with your Google Calendar.
-
Workshops and courses
GHGA Webinar: Understanding Genetic Discrimination

14 November 2024 @ 14:30 - 15:30
Online
-
Workshops and courses
Life Science Data Management: Planning workshop
20 November 2024 @ 09:00 - 15:00
Online
Data management Data curation and archival FAIR data Data handling Data deposition Data management planning DMP Data managment plan RDM NeLS TSD sensitive data data protection Compliance Identifiers data life cycle metadata Data storage data publication Data Protection -
Meetings and conferences
Assessment of crops and forests performance across scales
22 November 2024 @ 14:00 - 16:00
Online
-
Empowering Data-Driven Healthcare: A Formal Consent Framework Using FHIR
25 November 2024 @ 11:00 - 12:00
Hybrid
FHIR Healthcare Interoperability Data Management data stewardship Data sharing Computational Biology Bioinformatics -
Meetings and conferences
Open de.KCD Project Meeting and Networking Event
29 November 2024 @ 13:30 - 15:30
Hybrid
Training infrastructure Training material Strategy Cloud Computing Cloud Research Environment networking -
Meetings and conferences
Biotic interaction in agroecosystems
29 November 2024 @ 14:00 - 16:00
Online
-
Meetings and conferences
Genotypes x environment interactions across scales
6 December 2024 @ 14:00 - 16:00
Online
-
Workshops and courses
LUMI Intro course 10.-11.12.
10 - 11 December 2024
Online
High Performance Computing for Companies LUMI Supercomputer
Note, this map only displays events that have geolocation information in
TeSS.
For the complete list of events in TeSS, click the grid tab.