Events
Subscribe to Filter
Importing into Google Calendar
In the left-hand column of the Google Calendar main view, click the arrow to the right of "Other calendars" and click "Add by URL". In the form that appears, paste in the URL from the box above, and click the button to confirm.
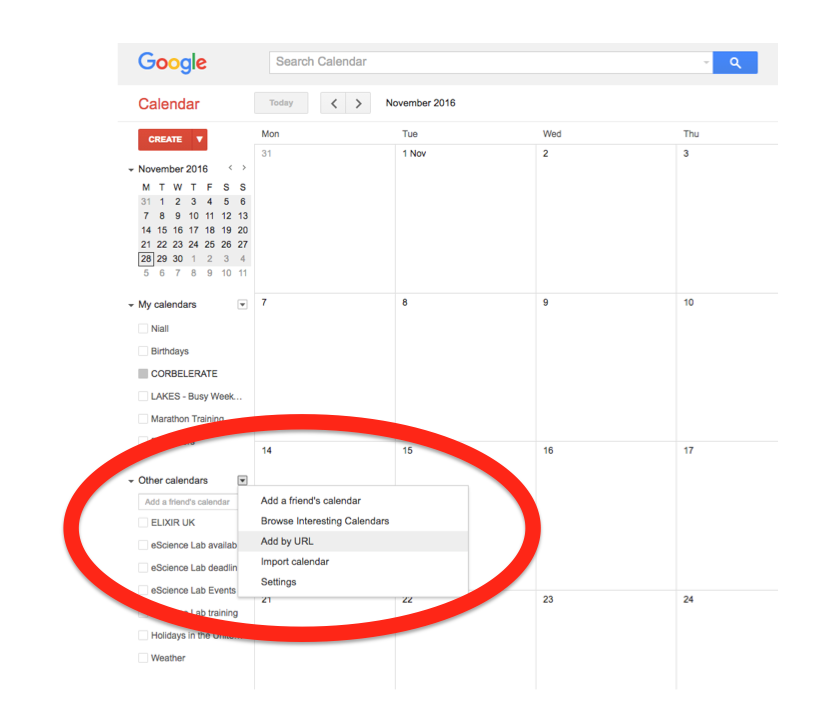
Please note, it may take a while for newly created events in TeSS to synchronise with your Google Calendar.
-
Workshops and courses
Systems biology: from large datasets to biological insight

23 - 27 October 2023
United Kingdom
Face-to-face
Systems biology Network analysis Machine learning Deep learning Network inference Logic modelling Data integration Multi-Omics Factor Analysis MOFA -
Workshops and courses
Microscopy data analysis: machine learning and the BioImage Archive
22 - 26 April 2024
Online
Machine learning Bioimaging Image analysis Bioimage analysis Machine learning models Scientific computing Light microscopy Electron microscopy -
Workshops and courses
Systems biology: from large datasets to biological insight
10 - 14 June 2024
United Kingdom
Face-to-face
Systems biology Network analysis Machine learning Deep learning Network inference Logic modelling Multi-Omics Factor Analysis Data integration MOFA -
Workshops and courses
I made my code open - now what? Steps to a thriving open software project
23 October 2024 @ 09:00 - 17:00
Online
Software management FAIR data Open science Machine learning Europe PubMed Central ChEMBL: Bioactive data for drug discovery Protein Data Bank in Europe Literature (literature) Open source tool Open source code CAPITAL project -
Workshops and courses
Prompting 101 - A Beginner's Guide to Communicating with LLMs
20 November 2024 @ 09:00 - 17:00
Tartu, Estonia
Face-to-face
Machine learning Natural language processing ChatGPT LLM -
Workshops and courses
Microscopy data analysis: machine learning and the BioImage Archive
31 March - 4 April 2025
Online
Machine learning Bioimaging Image analysis Bioimage analysis Machine learning models Scientific computing Light microscopy Electron microscopy
Note, this map only displays events that have geolocation information in
TeSS.
For the complete list of events in TeSS, click the grid tab.